by Gino | May 5, 2017 | Master Instructor Blog

If you are a data-geek, you’ve stumbled onto the right blog. If you love learning about the science behind your training, you should find these posts pretty interesting. If you’re the type who likes to not only know what, but has to know WHY training is prescribed in one way rather than another, your “show me” approach to training should be appeased in our Evidence Based Cycling.
However, if you just like to ride, and not worry about heart rate, not care about your power to weight ratios, could care less about threshold & VO2, then you might not get much out of Evidence Based Cycling.
Being patterned after the practice of evidence-based medicine, we (Cycling Fusionâ„¢) are defining Evidence Based Cycling in the following way:
The practice of Evidence Based Cycling is a process of life-long, self-directed learning in which caring for our own riders creates the need for cycling relevant information about diagnosis, prognosis, training methodologies, and other cycling and health issues that we can measure and improve.
Training protocols and methods used by Indoor Cycling Instructors and Outdoor Cycling Coaches that ascribe to Evidence Based Cycling are based on the following:
Integrating individual expertise with the best available external evidence from systematic research, but neither expertise nor external evidence alone is enough.
By individual expertise we mean the proficiency and judgment that we individual instructors and/or coaches acquire through relevant experience and practice.
This expertise is also reflected in thoughtful identification and compassionate use of individual rider life situations, rights, and preferences in making decisions about their training.
By best available external evidence we mean cycling relevant research, often from the basic sciences of training, but especially from rider centered research into the accuracy and precision of diagnostic tests.
External evidence can confirm previous theories or studies, but sometimes it can invalidate previously accepted methods and understanding. In these instances, it replaces them with new ones that are more powerful, more accurate, more efficacious, and safer.
Without cycling expertise, students risk becoming tyrannized by external evidence, for even excellent external evidence may be inapplicable to or inappropriate for an individual rider.
Without current best external evidence, training methods may become rapidly out of date, sometimes to the detriment of riders.
Evidence Based Cycling converts information needs into answerable questions:
Track down, with maximum efficiency, the best evidence with which to answer them.
- From the first hand accounts of coaches, instructors and riders the diagnostic laboratory from research evidence, or other sources.
- Critically appraise that evidence for its validity (closeness to the truth) and usefulness (cycling specific applicability).
- Integrate this appraisal with our personal cycling expertise and apply it in practice.
- Evaluate our performance.
- Report back and record the results for others to benefit from.
No doubt, this definition and outline will be refined and/or expanded over time, as we continue to build a practice of Evidence Based Cycling. With the last 3 posts amounting to essentially a foundation or background for why we believe this is something worth writing about and implementing, the next post will be an example of how anyone can implement their own Evidence Based Cycling program.
Originally posted 2012-04-13 13:34:50.

by Gino | Feb 25, 2014 | Instructor Training, Master Instructor Blog, Training With Power
Different Methods Same Skewed Results

A different approach with a professional researcher still produced mixed results
Let’s start with the good news. I’m sorry, I was completely pulling your leg. I really don’t have any good news. I know, that’s terrible — you can throw pencils and small farm animals at me next time you see me. I was really looking for the good news in these results and I just can’t find any. This last series of retesting the same three bikes to see if we could garner the same or similar results each time we measure the bike has led to 2 out of the 3 bikes demonstrating a “skewed distribution” of data. In other words, data that you could not and should not try to predict with because they are in a word, unreliable. That means my hope for creating a “handicap” for each bike to render them even and fair for comparisons and competitions is not possible.
Statistical measurements often use Standard Deviation to determine how much variation there is in the individual readings or occurrences of data (in our cases — the differences between the actual power and the measured power). There is something called the “Emperical Rule” (http://www.pmean.com/08/SdTooBig.html) “…it says that approximately 95% of the data lies between plus and minus two standard deviations of the mean.” This 95% rule is for data with a “normal distribution”. This is what we were hoping for when we measured the same bike several times.
Please remember, this stage of the research was RE-measuring the same bikes, not measuring the differences in power between bike computer and actual power of the power pedals. We knew all along the pure accuracy would not be there, we were simply hoping that the amount or degree to which it was “off” would be consistent.
So getting back to our “Empirical Rule”. There is a corollary to that principle, and that is “If a non-negative set of data (which we have with our power numbers study) has a standard deviation that is more than half of the mean, it is an indication that the data deviates substantially from a bell shaped curve. Almost always this is an indication of a skewed distribution.” The second column to the end (right side) indicates if the distribution of repeat, same bike readings has a skewed distribution or not.

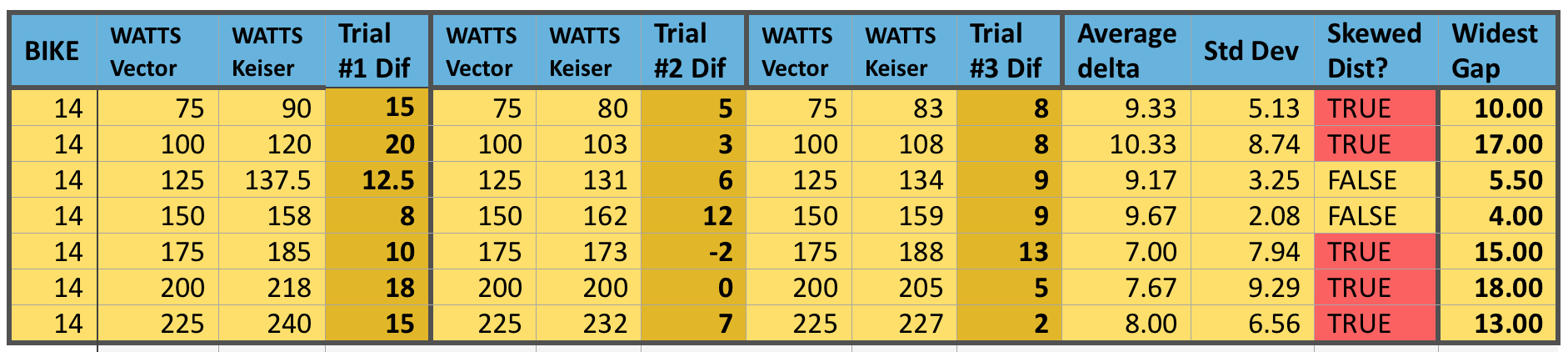
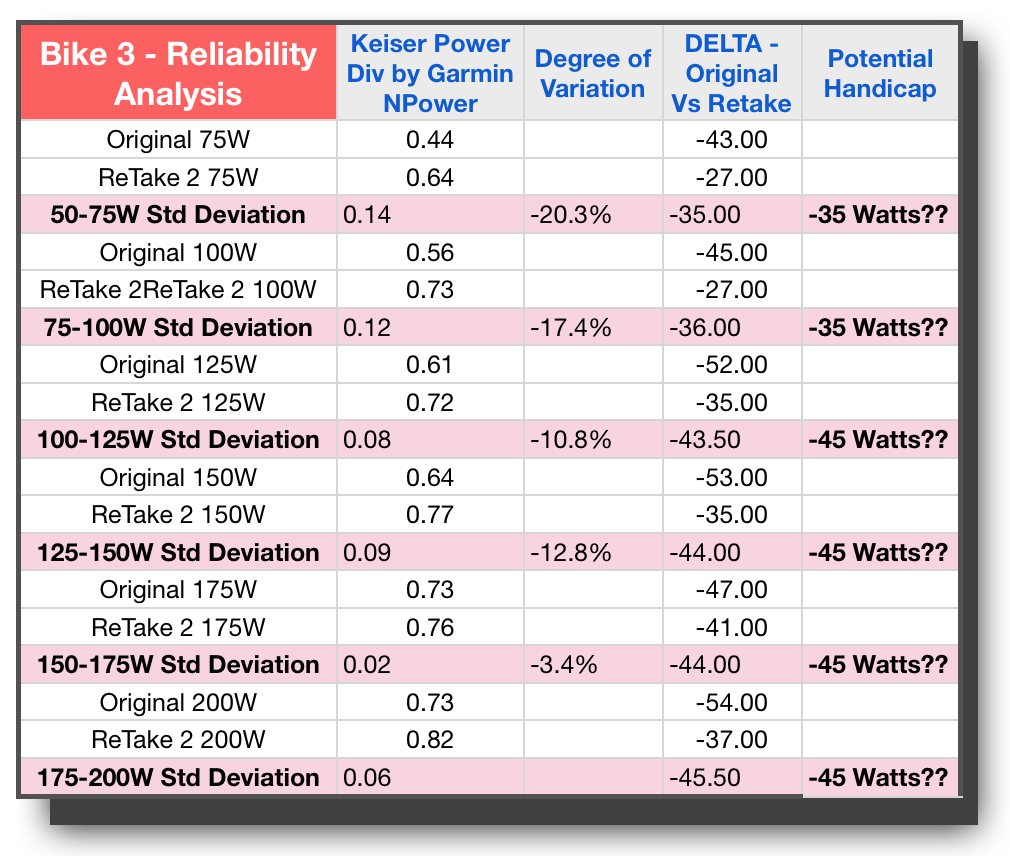
Bike 14 tested 3 separate times, looking for consistency between tests, for reliability to set bike handicaps.
With bike #14, it is notable that Trial #2 and #3 area actually fairly close except for at the 175 Watt stage. However, when we add our first set of numbers to the analysis, all but two wattage levels are skewed. If we just consider 1 bike, we might make a case that if we were to do 5 to 10 repeat trials, we might see these better numbers continue. This was something Sarah (our statistician) suggested as a next possible phase of the research; to conduct a much higher number of trials to see if we begin to see greater consistency or normalcy to the data.
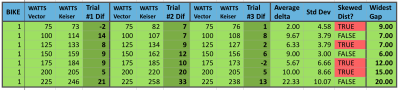
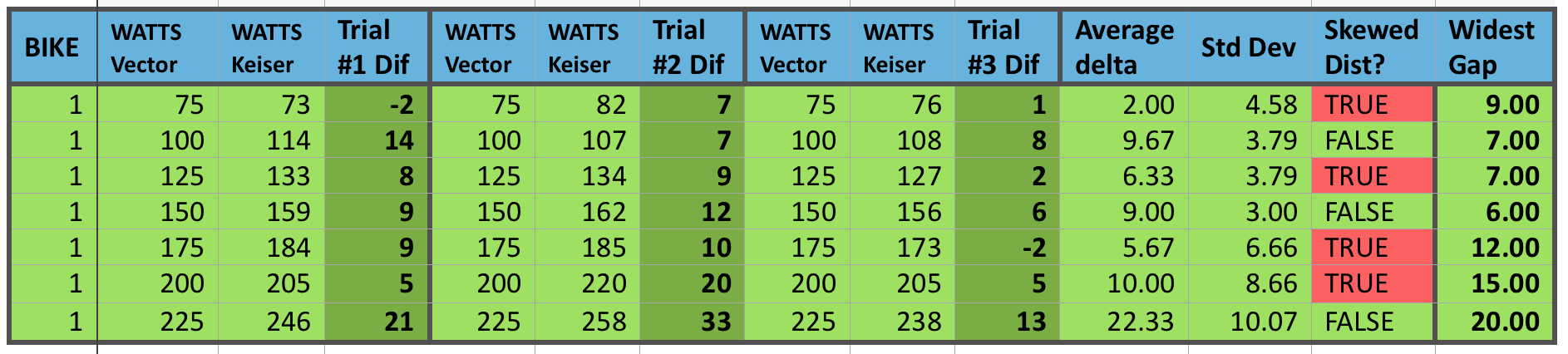
Bike 1 tested 3 separate times, looking for consistency between tests, for reliability to set bike handicaps.
Again, with bike #1 we have only 2 out of 7 different wattage stages that are not demonstrating a skewed distribution of data. At a “gut feel” level, I was hoping to see less than 5 watts difference between measurements of power when it was the same stage. I was willing to accept a difference of 10 watts since accuracy was still not the main driver here. However, again we must remember this is not the power difference, but just the repeating values on the same bike — how reliable it is for a consistent representation of power. Unfortunately, 30% of all the individual stages rendered differences greater than 10 watts and statistically 4 out of the 7 stages were considered skewed.
A Glimmer of Hope?
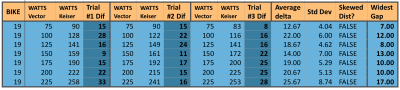
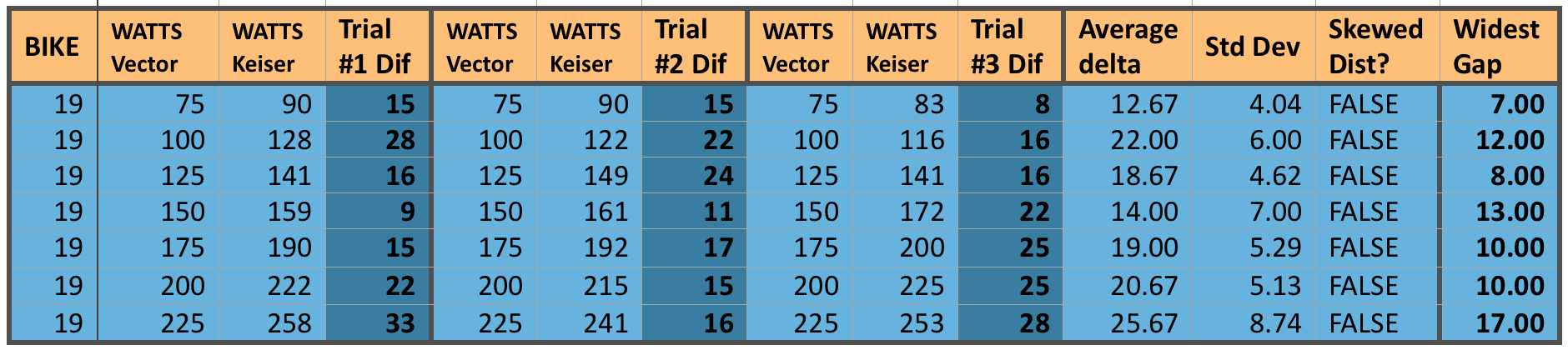
Bike 19 tested 3 separate times, looking for consistency between tests, for reliability to set bike handicaps.
Our last bike does seem to show a glimmer of hope though. While this specific bike had some of the largest differences in actual to measure power differences (in the 15 to 25 watt range), at least it showed those big swings fairly consistently. Notice how small the Standard Deviation is compared to the average delta (simply means the difference) among all three trials. This thus demonstrates a more “normal” distribution and could indeed support a type of “Power Handicap”.
So perhaps I have saved the good news for last. Maybe… just maybe, this means that some bikes would be amenable to a type of handicap while others may not. Picking up on Sarah’s suggestion, a lot more research (translate that — time spent repeating tests on the same bikes, many bikes) might lead to a set of bikes that are “good to go” with a handicap, and a set that are not. Naturally, being the proverbial curious cat, I would want to find out if there is some reason the unreliable bikes are that way. We might even be able to take those bikes through a preventive maintenance routine, recalibrate them to the furthest extent, and repeat the same retests. If we come up with a majority of the bikes being statistically solid and reliable, then we have not only created a handicap system, but we’ve validated the calibration method.
However, having spent as many hours as I have so far on this project, I’ve hung my lab coat up for now, so you won’t be blinded by science from me or a while. If I were Keiser corporation though, I believe I would have a vested interest in picking up where this research left off. I have moved this conundrum past the “blank page” and created a possible path that they could very well negotiate to a workable solution for their clients. Perhaps many clients don't care. I get that – not everyone even uses the training tools. Yet they were bold enough to lead the industry with power and have played a major role in seeing this industry change for the good. I believe Joe Public is becoming increasingly more savvy when it comes to training, and this is rapidly becoming a more educated marketplace. Especially if they consider just their own clients, such an undertaking should be received very well, supporting their image as a company that takes training seriously enough to put in the time and energy to make it right.

by Gino | Feb 11, 2014 | Instructor Training, Master Instructor Blog, Training With Power

It's time to look at the data gathered so far.
Time To Dig In
So we’ve painstakingly done everything possible to setup and prepare our methods for a solid research project — at least as solid as any “non-university” research setting can hope for. We’ve not only established a consistent protocol for conducting the tests, but we’ve also made sure to not do too many in any one day, nor to use different testers to eliminate potential influences to our results.
Once we executed these tests on about a dozen bikes, I wanted to start to analyze the data, and that’s when it occurred to me that we needed to make sure that the numbers I was about to analyze were reliable and repeatable from bike to bike. My last post demonstrated the process of re-testing to insure that very thing. After doing retests on about 6 of the 12 bikes, it is now finally time to review the data and see just what is what.
Let’s Start With The First 2 Bikes
Each day I tested only 2 bikes — to make sure I was fresh each time. So naturally, my first peak at the numbers (and I try not to look at them until I am well into the research so that initial impressions do not subconsciously alter my performance as more tests are conducted) came after these first 2 retests. Remember, I’m into the research project a couple of months now without letting myself “have a taste” — that’s pretty tough for a data-geek like me ☺. So below you will see the first two bikes retested. Let’s go over the columns so we can understand what we are looking at.

1st Keiser m3 Indoor Cycling bike with power to be tested & retested.
2nd Keiser m3 Indoor Cycling Power bike tested with the Garmin Vector Pedals
The first column represents the 25 Watt stages that were used to get the average power numbers from. These were “settled into” for 2 to 3 minutes at each of these stages. More specifically I used the Keiser console to establish a steady wattage level during each stage, and then once the 2.5 minutes were up, I stopped the keiser to get the true average (which typically was within 5 watts of the target) and we also lapped the Garmin so it would later give us the average or “Normalized Power” (NPower is how I have referred to it on the table) from the Garmin Vector Power Pedals.
Column: Keiser Power Div by Garmin NPower
By dividing the calculated power of the bike by the measured power from the Vector power pedals, we will see by percentage just how close they are to each other. Remember, we are not concerned about pure accuracy per se — we know the calculated power is going to be inaccurate by its nature — we simply want to know how much it is off, and if that amount is reliable every time re ride that bike. Each percentage is a reflection of both bikes at a specific wattage on one test.
Column: Degree of Variation
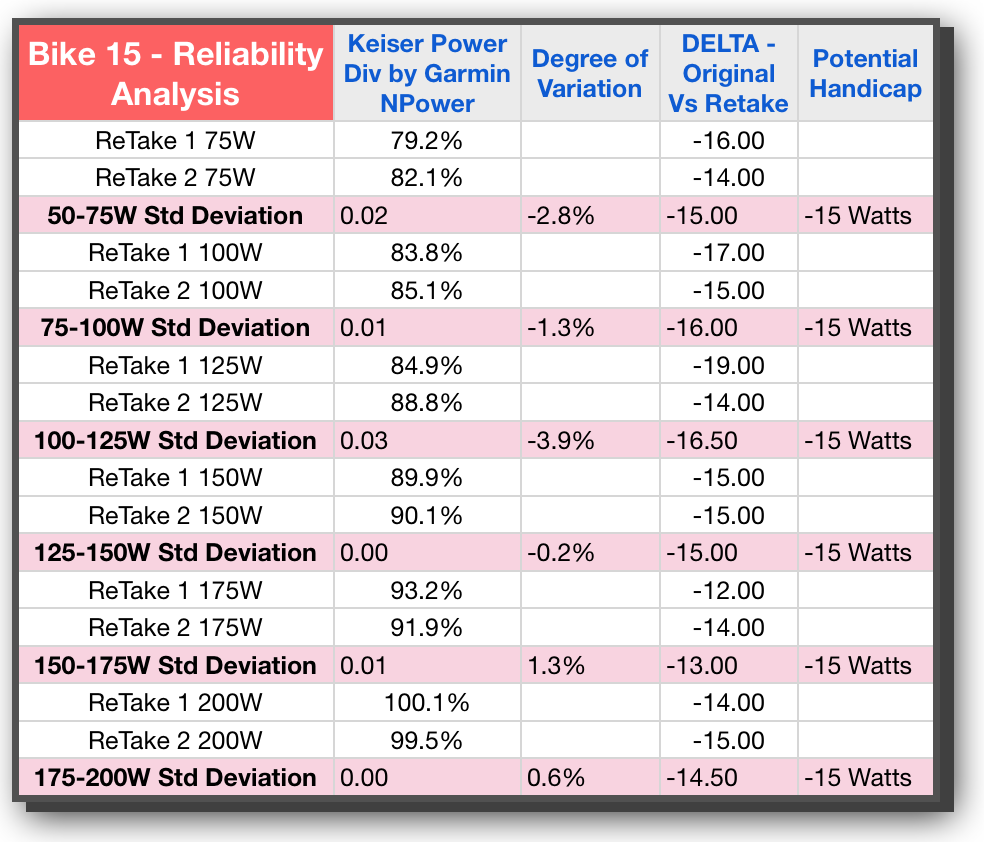
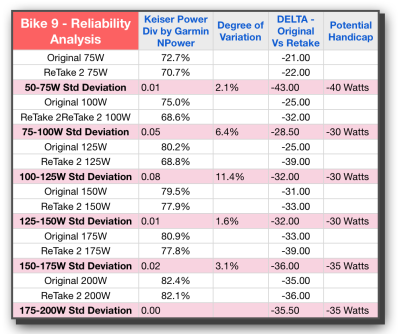
If we now take the difference between the first test and the next, we can get at how reliable the bike is between test sessions. This is the KEY metric for our purposes during this phase of the study; validating that each bike within itself is reliable. From a practical standpoint, we need the difference between tests to be low if our handicaps are going to be valid and useful from one class to the next. In looking at both Bike 15 and Bike 9 we see that these are indeed fairly low — an initial good sign — and there is only one instance where the difference is over 10%. That’s actually a lot less than I expected.
Column: DELTA Original vs Retake
This is a “pre-handicap” column — showing the exact wattage differences at each stage of power averages. While this will produce precise numbers with decimals, we know that a practical application of handicaps would likely need to be in increments of 5 so that the math is easier when performing that handicapping in ones head. We could also use this to send to an automated system if one was ever created that could account for bike variations in the software (an insightful feature I would create if I were the purveyor of such software).
we use this column to evaluate the exact differences and averages before we designate a specific handicap number.
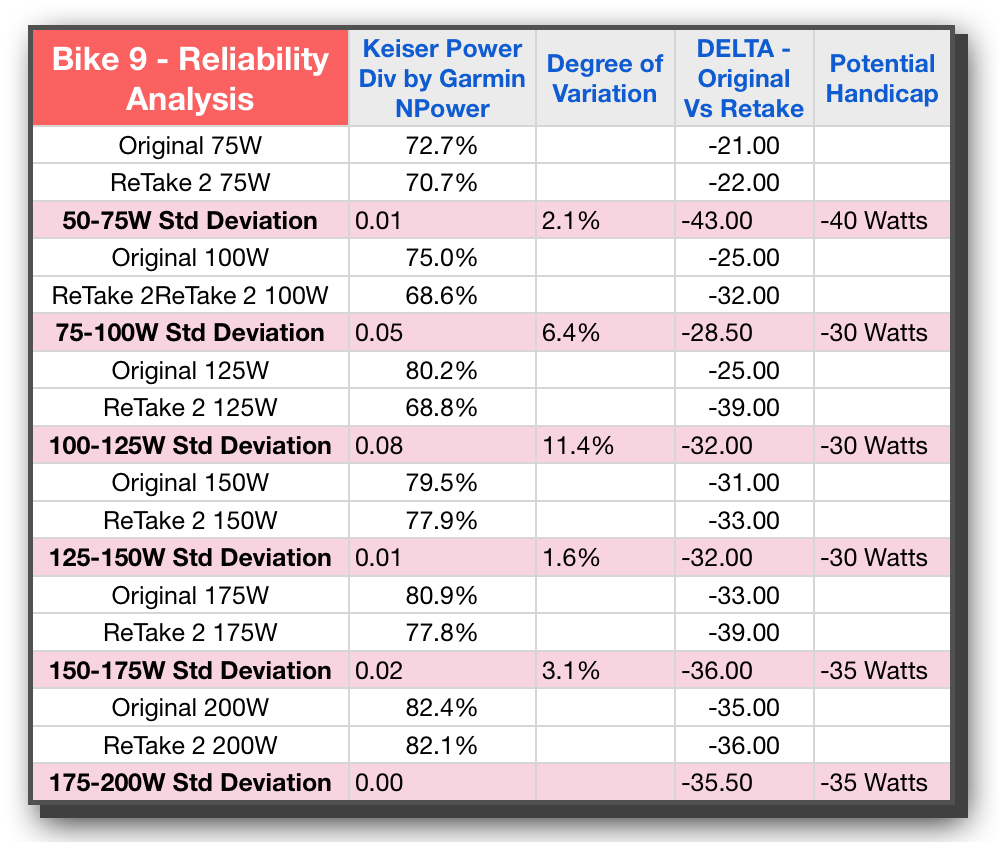
This column is the one that also really shows the amount of variation from one bike to the next. On Bike 15 we are averaging in the teens with wattage differences, whereas Bike 9 is averaging in the 20s and 30s. That’s quite a spread.
Column: Potential Handicap
This column would represent the entire motivation and impetus for all of the time and energy being spent on this research. We want to handicap the bikes! If you’ve read my eBook on Power (if not, no worries an updated iBook is due out soon — shameless plug apologies ☺ ), you will know that Power is not linear in its progression. As such we can not just use one number as the handicap and apply that to all wattage levels. If you look at all 4 bikes, you will see, with the exception of Bike 15, the differences get bigger and bigger as the wattage level increases. This is the exponential nature of power and the reason why I propose a handicap value for every 25 or 50 watts.
How About Some Analysis
Up to now, we’ve only sprinkled the analysis or possible conclusions as I’ve described each column. However, in order to even think about drawing conclusions, we will need more data points than just 2. Lets’ show four more bikes so we can see if there are some patterns emerging when we have 6 total bikes and their retests — giving us a total of 12 tests or sets of data points to consider.

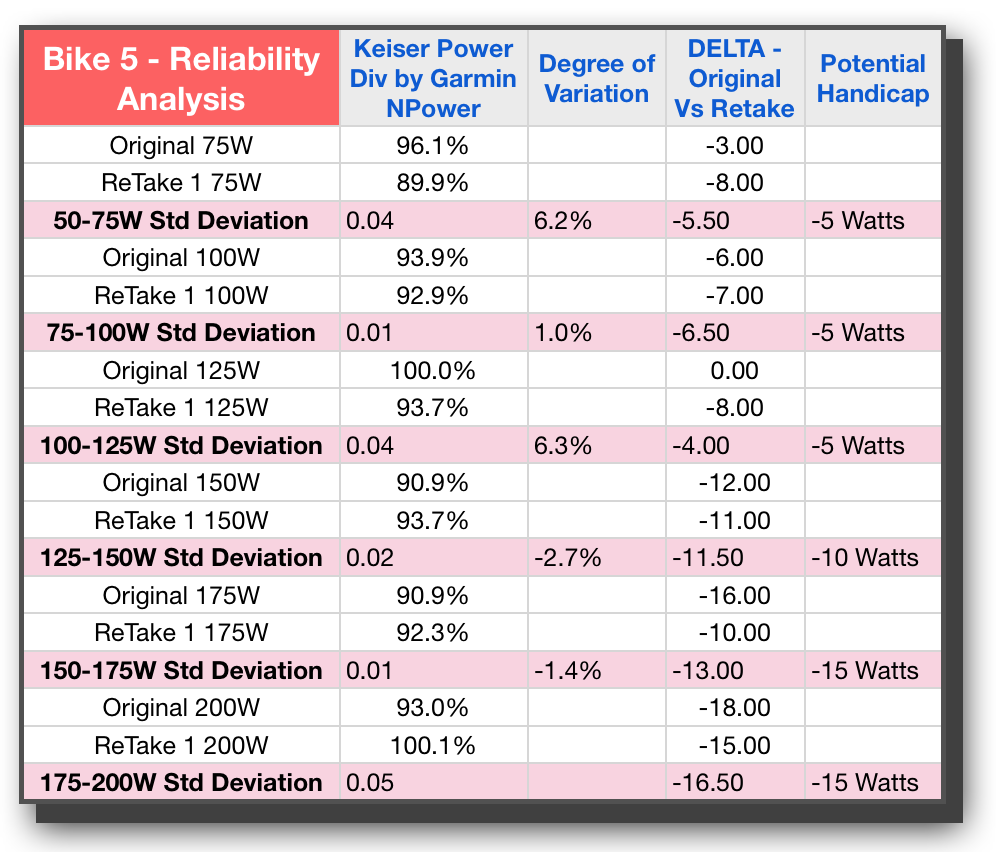
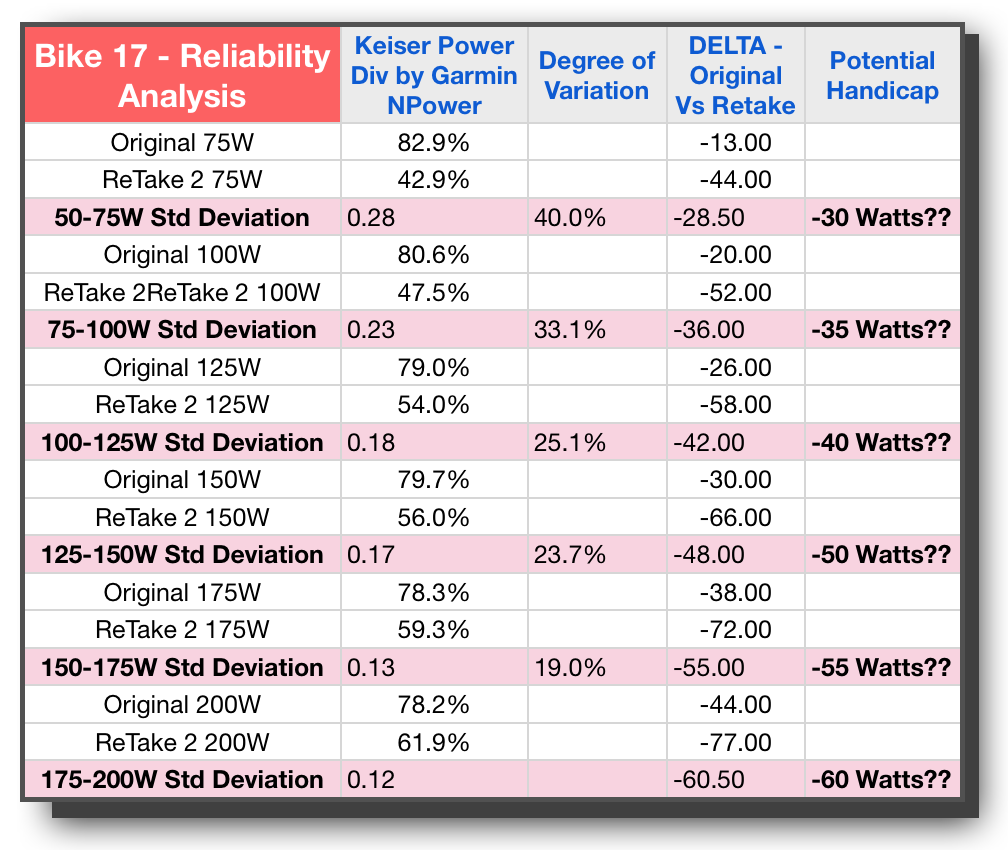
Looking at Bike 5 I’m feeling pretty good that it’s similar to #9, this time with all variation under 10% and the good power-like escalation of Potential Handicap wattage going up as a power curve would reflect. Taking a look at Bike #17 though, and I had to do a double take — WHAT?? or should I say “WAATTT!” The degree of variation is crazy. Not only that, even looking at it from a practical perspective, the Potential Handicap, aside from being huge in the 30 to 60 watt range, is simply not close to either of the trials in this study. While 30 Watts may indeed be the average between the two tests, with one being 13 and the other being 44, who knows if 30 will be too much or too little. In fact all of the stages are reflected as pretty wild for Bike 17.

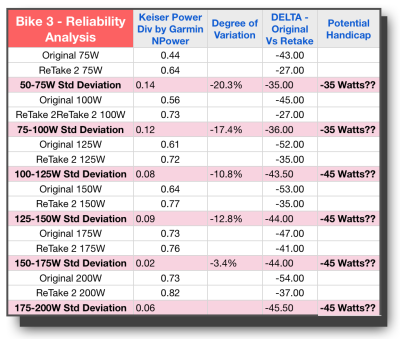
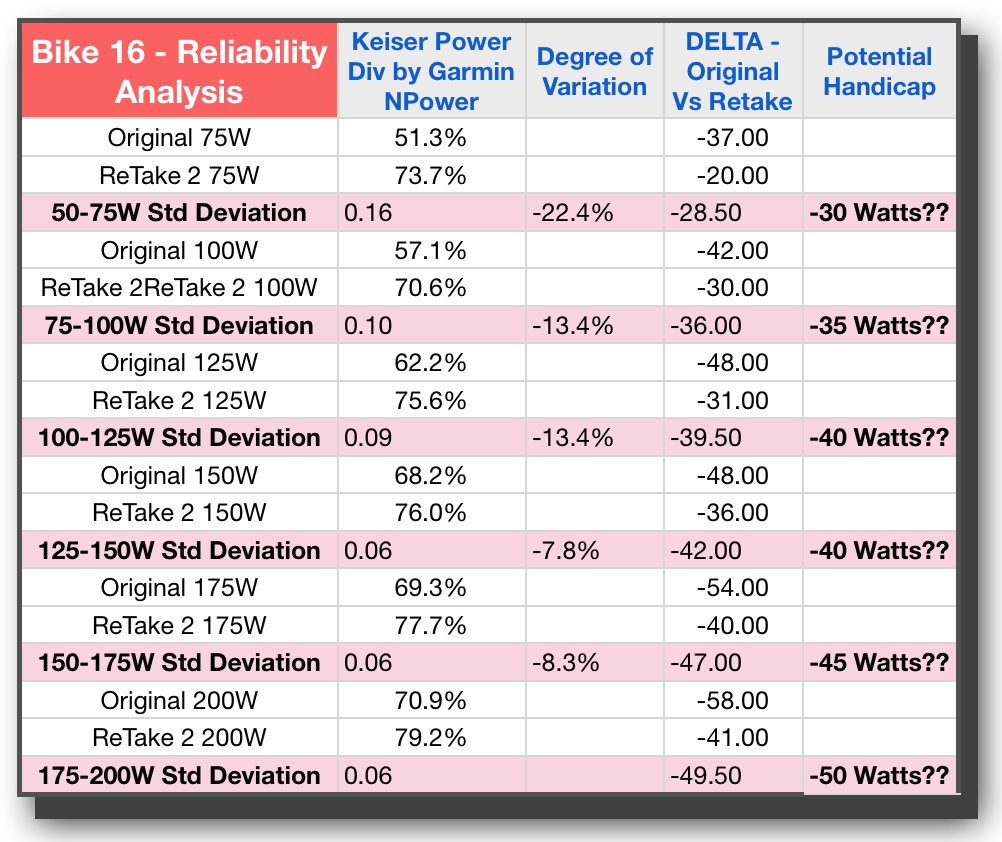
Unfortunately the bad news continues with Bike 16 and Bike 3. Both of these bikes have variations well above 10% and similar wide swings in Watts for the original delta between tests. In addition, we have bike #3 not demonstrating the proper power curve through the last 4 stages, but instead settling into one consistent difference in wattage.
Looking again specifically at these last 3 bikes, and there is no way I would be comfortable handicapping these bikes and expect it to be consistent. So all in all, we have 3 bikes that look like they would lend themselves to reliable handicaps, and three that do not. With a split decision like that, we are all but a hung jury here.
Since I recognized that I might be the problem — I am the only one conducting the tests – and while it stands to reason I would get better and more consistent over time not less, I did not want to rule that out. This data left me scratching my head more than anything else — more questions that need to be anwered. It was time to bring in bigger guns than I have.
The next blog will have another video where we brought in a professional statistician to help us get to the bottom of this.

by Gino | Feb 5, 2014 | Instructor Training, Master Instructor Blog, Training With Power

Making sure this process is repeatable with each bike tested is essential to our objectives.
Let’s recap what we’ve done so far in our video blog series:
1. We have introduced the whys and wherefores of this Indoor Cycling Power research project
2. We’ve shown exactly how the Garmin Vector pedals get mounted to the Keiser m3 indoor cycle bike
3. We’ve demonstrated from start to finish, the precise protocol used in conducting repeatable tests on each bike
4. Last week we stepped through the process for getting the data from both the Garmin bike computer and the Keiser m3 console (manually recorded) put into the a consolidated spread sheet.
Accuracy & Reliability Are Two Different Things
This week we move into the steps required to begin validating the reliability of our equipment and/or our process. This is as crucial a consideration as the pure accuracy of the data. If we can’t confirm that our process of measuring power is consistent on any one given bike from one day to the next, how can we expect to handicap the bike for accuracy with a number or even series of numbers for different wattage levels since an unrepeatable test would mean this handicap would not be valid from one day to the next.
http://vimeo.com/79224390
Indoor Cycling Power Accuracy & Validation Research from Cycling Fusion on Vimeo.
Consider the frustration of weighing yourself each day on a scale that can not show you 50 lbs from a 50lb weight from day to day. On some days you’ll be depressed while others you’ll be “woo hooing” all the while your weight has stayed the same. It’s an absolute critical component of our findings; to know what we are doing is repeatable and reliable. If it isn’t, we need to consider if the process is changing and causing the inconsistencies, or if the equipment is doing so. While I have tried to be more than methodical about every aspect of this process from pedal calibration to bike test execution, I will not rule out tester error or inconsistency for the moment. Let’s just first see how our numbers turn out before we decide which factor to consider (test process, or equipment variability).

Coach Gino Explains Why Validation & Reliability Are Important
The 2 video segments that make up this post are both quite short. The first one describes in detail how to unmounts the Vector Power pedals in order to use them on a second bike. It is important that we don’t just leave the pedals on and do multiple tests on the same bike. This would not tell us if that bike will be reliable one day to the next. We must first test other bikes, and then come back to bikes we’ve tested.
The second video segment is showing one complete test again (like our 2nd video), only this time on one of the bikes already tested from a previous session.
http://vimeo.com/79824570
Indoor Cycling Power Accuracy & Validation Research from Cycling Fusion on Vimeo.
by Gino | Dec 9, 2012 | Master Instructor Blog

One study down, a few hundred more to follow.
As a bit of “post-mortum” on our little EBC project, I asked all those participating in the study to share their own personal thoughts or observations with me. So as any experienced researcher will tell you, the actual collecting of the data can often reveal as much as the data itself.
There Is Joy In Repetition
No, I’m not talking about techno music, although the first time I heard that expression (about the joy in repetition) was in regards to Trance music. Getting back to our study, early on I heard feedback from some of our guinea pigs… er, I mean riders who found the Muscular Endurance work to be harder than they thought. They reported thatl making even just 2 sets of 15 minutes in Zone 3 and 75 RPM was more challenging than they thought. I also heard about how it got easier week after week. This was naturally expected from an RPE or “mental state of mind” is considered; doing something familiar will typically seem easier than doing something completely brand new. However, this later point emphasizes the real importance of having training tools.
Training Tools
In other words, if we consider that human nature tends to encourage us to work as little as possible to accomplish our objective (think efficiency, not laziness), in combination with our mental comfort with all things familiar, we run the real risk of depriving ourselves of a good training effect when these are at play in our physiological development or improvement as a rider.
If we put this in the context of our current study, if we did not heart monitors, we would not have been able to insure or insist that our heart rate remain within the range specified. If a training effect were to come into play (that is, we were to become stronger in some way from doing the M.E. drills), without a heart monitor, we might not have increased our gear (remember, keeping cadence constant was a requirement) as the training effect occurred, and thereby inadvertently reduced the amount or the longevity of that same training effect.
Not Just for Curiosity & Science
I also heard from at least two people that if they had not done the study, they would not have been as well prepared for a late season big ride they had scheduled. The combination of the type of training and the fact that it was an obligation to get through each of the study weeks was enough to motivate them to keep training.
In general I have found that most of my study participants gain a good deal of benefit from our little research projects. The worst case scenarios seem to be that they don’t improve, but they are no worse off than when they started. It’s generally a neutral to very positive both in experience and results.
Parting Thoughts
I have answered the previous comments through this graphic below. However, these answers may be wholly unsatisfying. Remember, the reasons this entire blog started and I coined the phrase Evidence Based Cycling™ is because the same studies are used by different coaches to emphasize different things or with completely different conclusions. It’s not exactly religion, it is science, but believe me there is way more subjective interpretation involved than many are willing to admit to.
I will not claim to be a professional researcher, nor the final word on any subject for that matter. But I will also not hide behind the science and say that it must and only can say this or that. It is what it is, look at it, learn about the subject, then draw your own conclusions.
At a minimum, I hope you are encouraged to dig in and do your own studies. Learn to question everything including everything written in this blog — but don’t just be a movie critic — get in there and make your own movies!
.